Сортировка
Завершая раздел по операциям, нам остается только отсортировать результаты.
Предлагаю вывести таблицу агрегатов в обратном лексикографическом порядке по имени страны.
val result = join.select($"country", $"value")
.groupBy($"country")
.sum("value")
.select($"country".alias("key"), $"sum(value)".alias("value").cast(StringType))
.orderBy($"key".desc)
Заодно вы можете увидеть альтернативный подход к назначению псевдонимов и приведению типов.
DAG изменился не сильно, по сравнению с предыдущим примером (и это прекрасно!). Можно заметить, что сортировка выполняется экономно, в сам конце, уже на результирующей таблице.
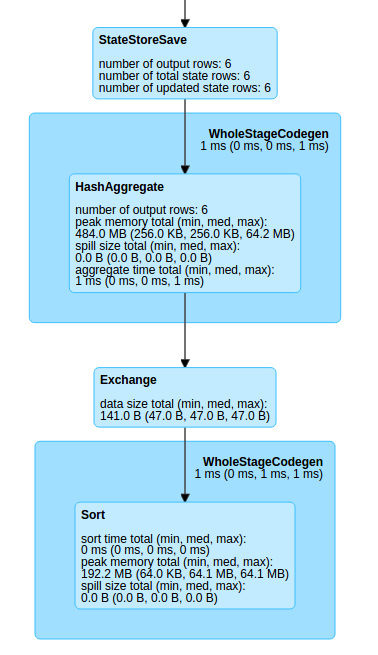
Сортировка без агрегации
А вот эта операция может стать нам довольно дорогой и с точки зрения ресурсов CPU и сети, и с точки зрения сохранения промежуточных результатов в памяти.
Если мы отказываемся от агрегации, то время вернуться обратно, в AppendMode.
Еще раз, полный код примера:
object Ex_5_OrderBy {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder
.master("local[2]")
.appName("SparkKafka")
.getOrCreate()
spark.sparkContext.setLogLevel("ERROR")
val stream = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "localhost:9092")
.option("subscribe", "messages")
.load()
import spark.implicits._
val dictionary = Seq(Country("1", "Russia"), Country("2", "Germany"), Country("3", "USA")).toDS()
val join = stream.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.selectExpr("CAST(key as STRING)", "CAST(value AS INT)")
.as[(String, String)]
.join(dictionary, "key")
val result = join.select($"country".alias("key"), $"value")
.orderBy($"key".desc)
val writer = result.writeStream
.trigger(ProcessingTime(3000))
.format("console")
.start()
writer.awaitTermination()
}
case class Country(key: String, country: String)
}
Данный пример скомпилируется, но обрушится в рантайме во время попытки построить план, и error message ясно будет гласить, что org.apache.spark.sql.AnalysisException: Sorting is not supported on streaming DataFrames/Datasets, unless it is onaggregated DataFrame/Dataset in Complete output mode;;
На сим и завершим.