Думаем головой при написании join
Даже если вы надеетесь на различные внутренние оптимизации Spark, не оставляйте попыток выразить свое намерение через код.
Например в ситуации, когда у нас есть два больших источника данных, которые мы соединяем, а потом фильтруем по какой-то общей колонке, лучше поменять порядок операций.
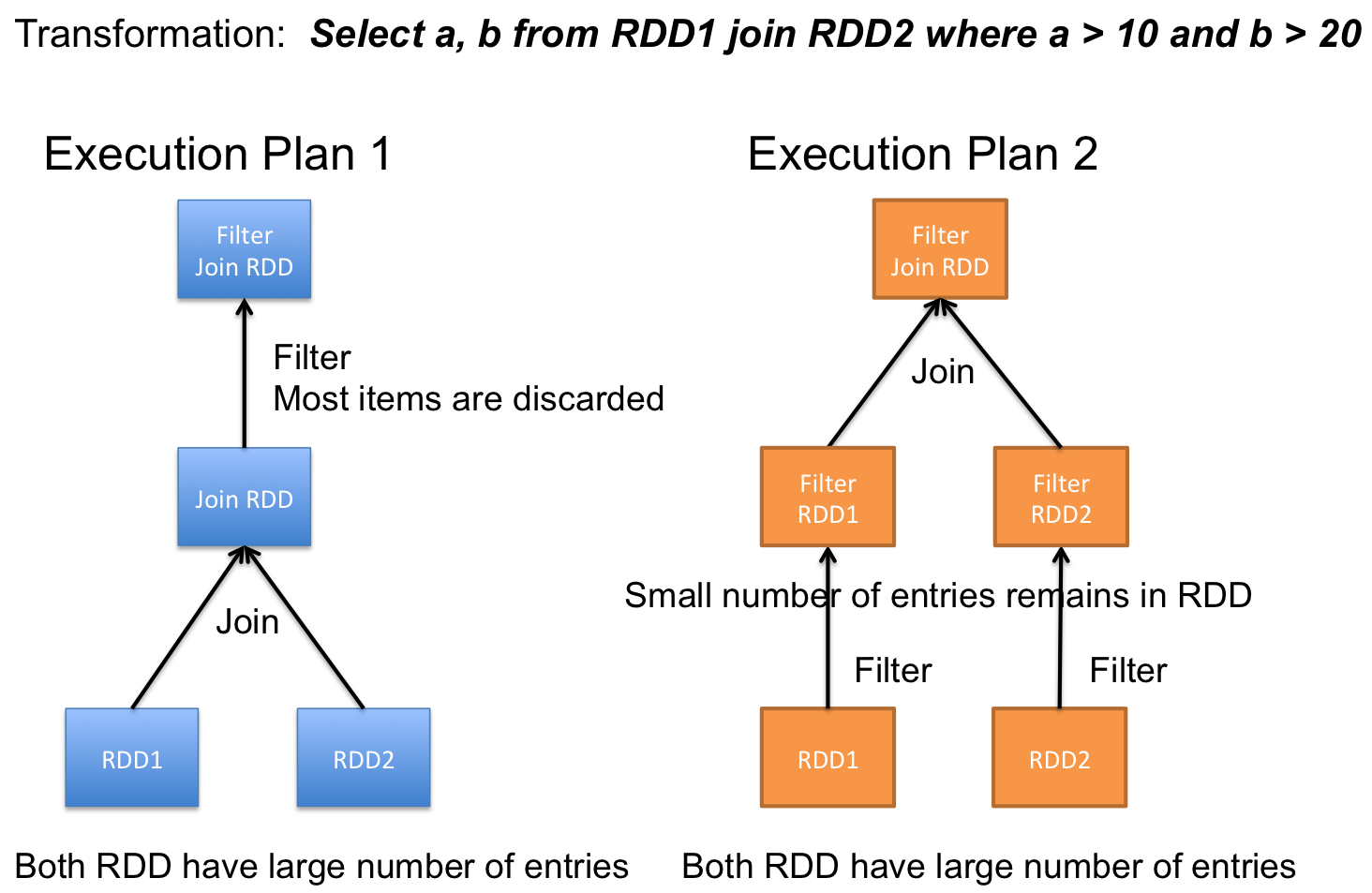
В современных версиях Spark, где даже для RDD применяются умные оптимизации, скорее всего будет задействована техника "push-down-predicate" и первый план превратится во второй.
Но зачастую, в очень сложных ансамблях запросов, оптимизации происходят не всегда удачным образом с точки зрения минимизации выделения памяти и CPU операций. Впрочем, этим в основном страдает код, использующий RDDю
Catalyst избавляет нас от многих бед в работе с DataFrames.