Операции над входящим потоком
Конечно, просто вывод информации на консоль, это не слишком интересно. Но давайте, сохраняя возможность быстрого вывода и проверки результатов, применим набор операций к входящему потоку. Начнем с простейщей фильтрации.
Эй, стрим, фильтруй ивенты!
Т.к. мы смотрим на все это, как на бесконечные таблицы, то и использовать нам пристало операции из DataFrame, а не RDD-подобные. Посему выбираем .where() и оставляем дишь те ивенты, где значение кратно 10.
val result = stream.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.as[(String, String)]
.where("value % 10 == 0")
Да и если заглянуть в веб-мордочку нашего Spark, а точнее - на закладку SQL, можно найти DAG, генерируемый для очередной джобы. Из 3000 строк получается 300, а затем выполняется проекция для вывода на экран. Сгенерированные планы прилагаются. 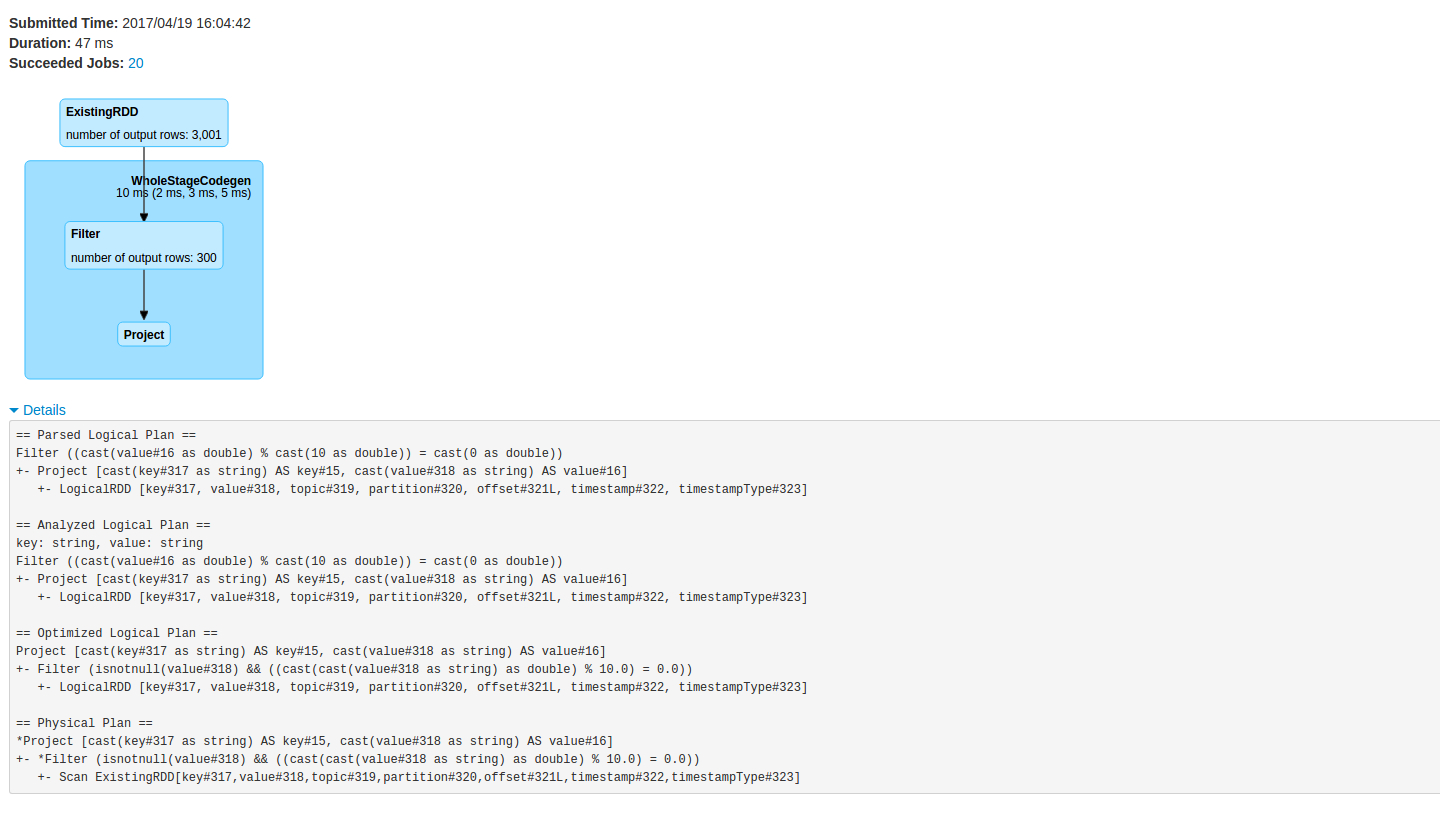
Но достаточно неудобно заходить в план, чтобы узнать количество отпроцессеных ивентов.
Кажется, на DataFrame была какая-то функция вроде .count()
Подсчет количества элементов во входящем потоке
Лихо пишем код и пытаемся его скомпилировать.
val result = stream.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.as[(String, String)]
.where("value % 10 == 0")
.count()
Однако, компилятор обязательно расскажет, что стрим из такого кода уже не получится.
Structured Streaming - штука пока экспериментальная и не все сочетания операций тут возможны и имплементированы. Спасибо Scala - мы узнаем об этом на этапе компиляции.
При помощи лишнего оператора groupBy можно добиться взаимоности от стрима и таки получить необходимый результат.
val result = stream.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.as[(String, String)]
.where("value % 10 == 0")
.groupBy()
.count()
Все скомпилируется, но в рантайме упадет с Exception in thread "main" org.apache.spark.sql.AnalysisException: Append output mode not supported when there are streaming aggregations on streaming DataFrames/DataSets without watermark;;
Перекрашиваем стрим
Что за outputMode, что за watermark? Никто нас об этом не предупреждал.
Про "режимы вывода" и "водяные знаки" будет говорено далее, а пока просто попробуем переключиться в CompleteMode - эта настройка задается как параметр writeStream
val writer = result.writeStream
.trigger(ProcessingTime(3000))
.outputMode("complete") <<== вот тут мы задаем OutputMode (по умолчанию стоит append)
.format("console")
.start()
Однако, после запуска выясняется, что результат монотонно возрастает. Да-да, CompleteMode выдает нам число ивентов, прошедших через него со старта джобы. Эдакий нарастающий итог. Иногда - это то, что нужно. Но сейчас мы хотели решить немного другую задачу (и на DStreams она решалась очень просто).
Проблемы решена частично, но еще любопытнее, как работает подсчет нарастающего итога.

А работает он через сохранение состояния и агрегации вновь вычисленного значения с предыдущим.
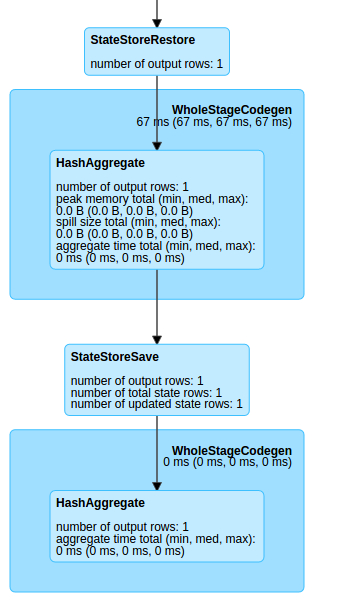
Ну и результат снова сохраняется для последующих объединений.
При этом любопытно, как простой логический план превращается в достаточно сложный физический план исполнения.
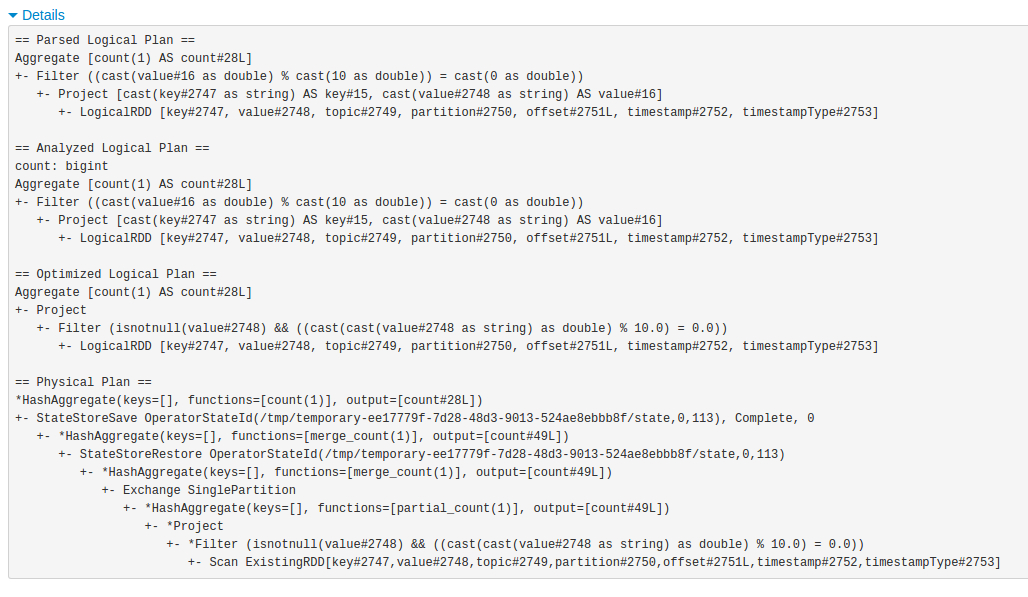
Count в AppendMode, пожалуйста!
Да, мы тут замечтались с этими картинками и ациклическими направленными графами вычислений, пора и честь знать.
Тут придется поработать глубоко и подробно с временными интервалами. Необходимо задать величину окна, за которое будут агрегироваться ивенты (выбрать равным triggerTime), кроме того для всех агргационных действий надо задать watermark, который можно установить равным 0 (чтобы упростить расчеты).
Но откуда взять timestamp? Благодаря чтению из Kafka, у нас он имеется и называется точно также.
Итоговый код выглядит так:
import org.apache.spark.sql.functions.window
val result = stream.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)", "timestamp")
.as[(String, String, Timestamp)]
.where("value % 10 == 0")
.withWatermark("timestamp", "0 seconds")
.groupBy(window($"timestamp", "3 seconds") as 'date)
.count()
val writer = result.writeStream
.trigger(ProcessingTime(3000))
.outputMode("append")
.format("console")
.start()
writer.awaitTermination()
Чтобы вся эта шарманка крутилась Spark-у требуется построить весьма серьезное дерево вычислений
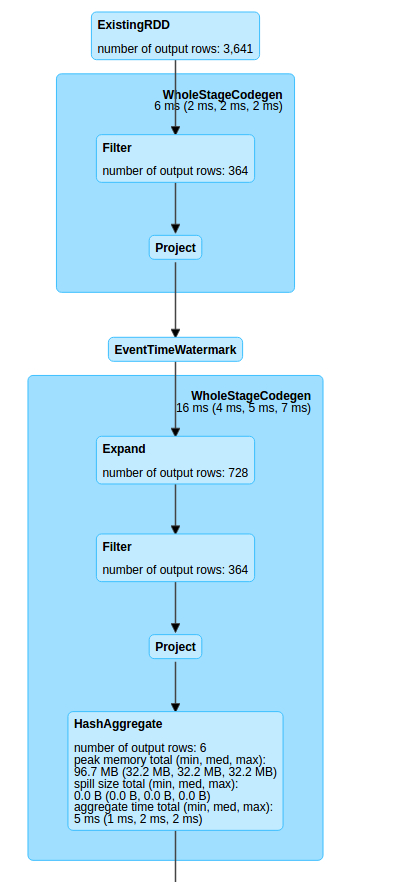
Мы видим странный оператор Expand, удваивающий количество строк (которые впрочем снова фильтруются и возвращаются к норме). Затем данные подгатавливаются для агрегации и передаются на вывод. Т.к. это appendMode, то и логика работы с состоянием здесь иная.
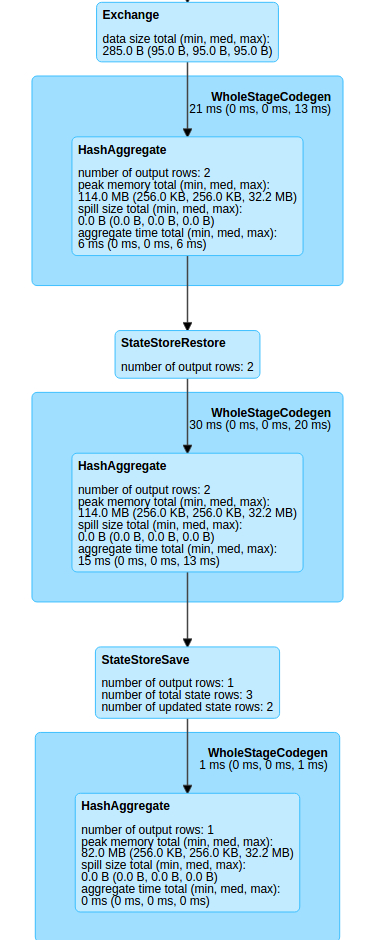
Итоговый набор планов велик и страшен, но пытливый спарковод, помня предыдущие стадии, сможет прочесть происходящее.
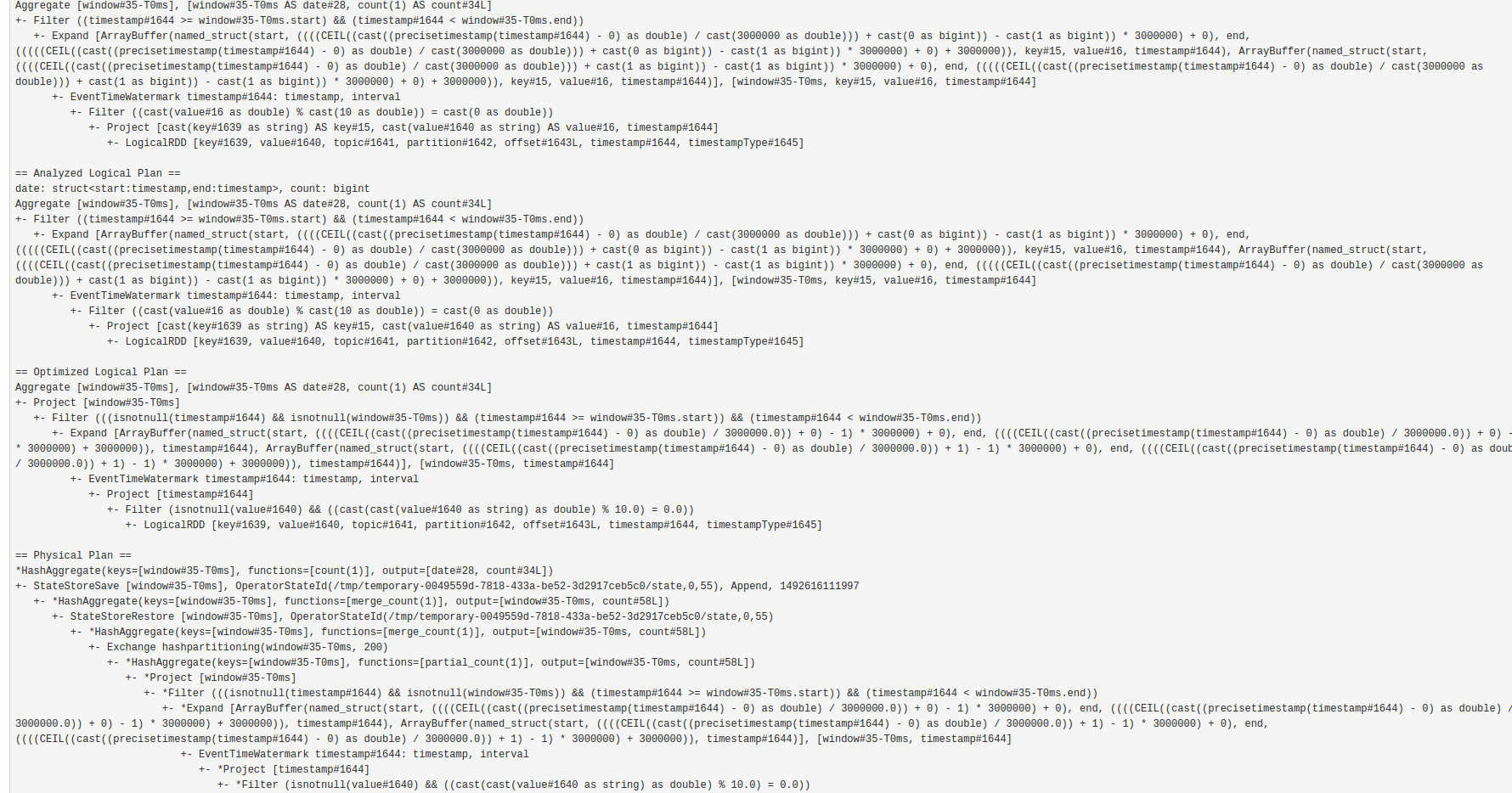
Положа руку на сердце, хочется закутаться в теплый пледик и убежать в мир Storm или DStreams.
Но самые отважные смогут продолжить путешествие дальше сквозь пока еще не зрелый, экспериментальный API.