Старые-добрые RDD
Любой туториал по Spark на просторах сети начинается с введения в RDD (реально дробленые данные). Я не ставлю перед собой цель их пересказать, но хочу вас уверить, что концепция эта достаточно простая и доступная для пониманию всем любителям функциональных языков и лямбд.
Во-первых, работать с RDD вы будете в старом-добром однопоточном стиле, а сам Spark уже за вас будет заботиться о распределении данных по кластеру. Как и в случае с MapReduce-каркасом, разработчику нужно описать только логику преобразований пар ключ-значение [key-value], но вместо переопределения функций нам достаточно определить лямбды (что возможно даже на Java) и передать их в одну из более чем 80 различных операций.
Во-вторых, вся внутренняя структура и кишочки RDD лежат на поверхности и вы должны держать в голове биение всех операций на два больших набора: "параллельный перенос" и "взял, смешал и вылил в форму". Я говорю здесь о wide/narrow зависимостях.
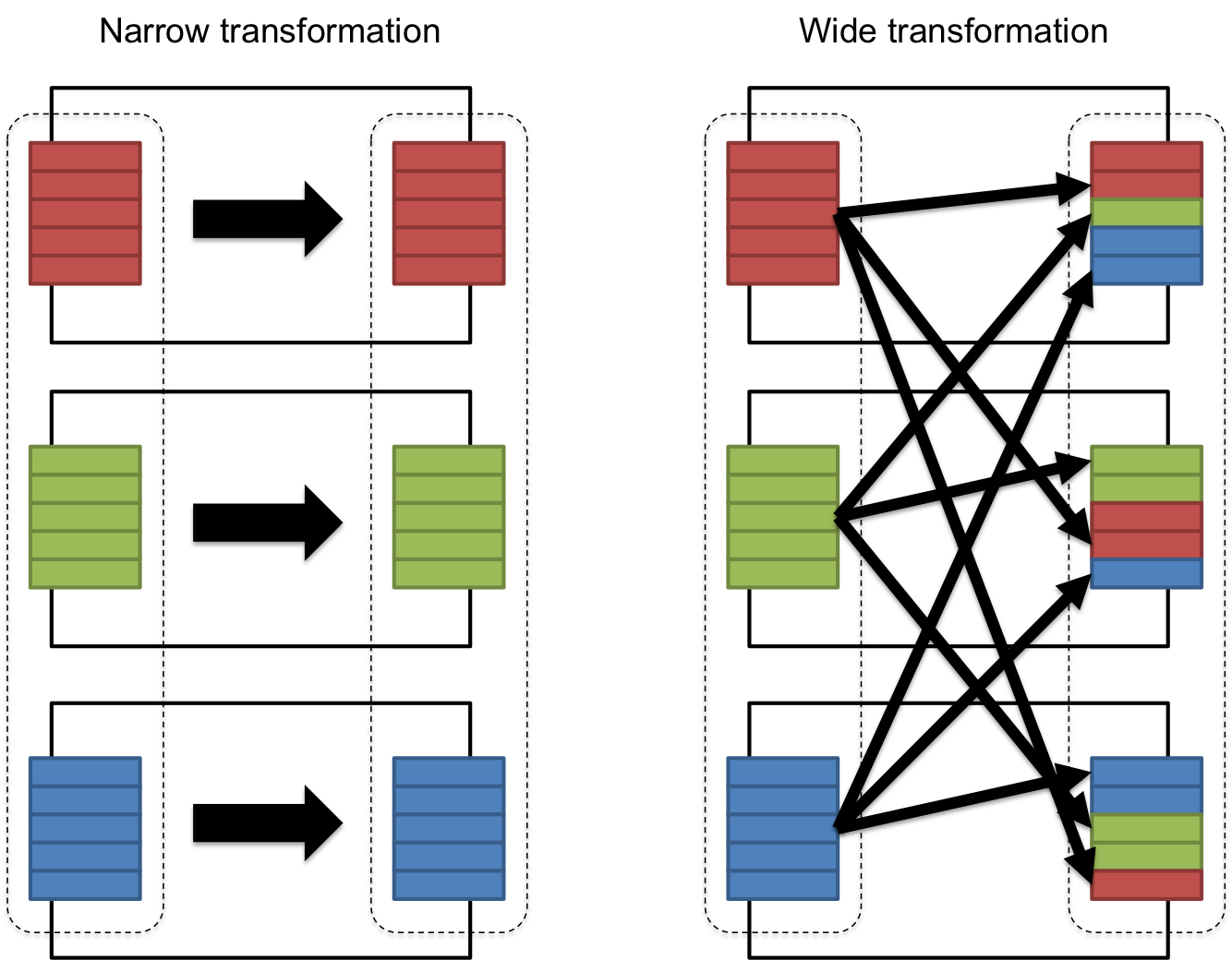
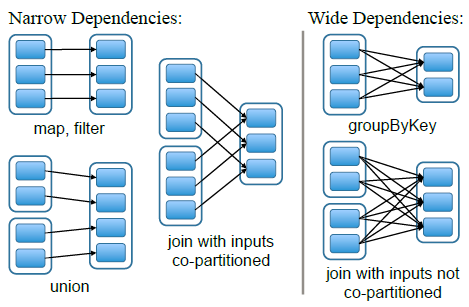
В целом, разработчик и сам, опираясь на теорию множеств, может догадаться, какая из операций вовлекает перемешивание ключей из разных источников, а какая может быть выполнена путем независимых параллельных операций на распределенной по кластеру коллекцией на входе, но в качестве подсказки я приведу еще одну картинку.
RDD значений и RDD пар ключ-значение
Генерируя очередную RDD при помощи оператора .parallelize(), вы наверняка замечали, что часть операций, таких как reduceByKey, join и т.д., вам недоступна.
val sc = spark.sparkContext
val r = 1 to 10 toArray
val ints = sc.parallelize(r, 3)
ints.<no groupByKey>
Дело в том, что RDD созданная из массива значений - это эдакая "неполноценная RDD", где коллекция значений только готовится стать либо набором ключей для индексации элементов, либо набором значений, для которых ключи будут получены как-то иначе.
Однако, стоит лишь добавить ключи (например 0 для четных, 1 для нечетных), как уже появится возможность делать группировки.
val groups = ints.map(x => if (x % 2 == 0) {
(0, x)
} else {
(1, x)
})
println(groups.groupByKey.toDebugString)
groups.groupByKey.collect.foreach(println)
Зачем нужно разбираться с RDD?
К сожалению, Structured Streaming имеет пока недостаточно зрелое API, поддержка DataFrames ограничена в MLlib, DStreams, GraphX. Да имеются проекты GraphFrames, TensorFrames, новый пакет ml. Но пройдет еще пару лет, пока весь функционал переедет на DataFrames. За это время накопится столько Spark-легаси на проектах, что эти знания пригодятся и тем, кто стартует в 2018 и 2019 годах на Spark-проектах.